жғіиұЎдёҖдёӘеҗ«жңү250дәҝд»Ҫж–Ү件пјҢеҚҙжІЎжңүйӣҶдёӯз®ЎзҗҶжңәжһ„е’ҢйҰҶе‘ҳзҡ„еӣҫд№ҰйҰҶпјҢиҖҢдё”д»»дҪ•дәәйғҪеҸҜд»ҘеңЁд»»дҪ•ж—¶й—ҙж·»еҠ ж–°зҡ„ж–Ү件иҖҢдёҚйңҖиҰҒйҖҡзҹҘе…¶д»–дәәгҖӮдёҖж–№йқўдҪ еҸҜд»ҘзЎ®е®ҡпјҢиҝҷеәһеӨ§зҡ„ж–Ү件е ҶдёӯжңүдёҖд»Ҫж–Ү件еҗ«жңүеҜ№дҪ иҮіе…ійҮҚиҰҒзҡ„дҝЎжҒҜпјҢиҖҢеҸҰдёҖж–№йқўпјҢдҪ еҸҲеғҸжҲ‘们дёӯзҡ„еӨ§еӨҡж•°дәәйӮЈж ·жІЎжңүиҖҗеҝғпјҢжғіиҰҒеңЁеҮ з§’й’ҹд№ӢеҶ…е°ұжүҫеҲ°иҝҷжқЎдҝЎжҒҜгҖӮдҪ жңүд»Җд№ҲеҠһжі•е‘ўпјҹ
ж‘ҶеңЁдҪ йқўеүҚзҡ„иҝҷдёӘйҡҫйўҳзңӢиө·жқҘдјјд№Һж— жі•и§ЈеҶігҖӮиҖҢиҝҷдёӘж–Ү件е Ҷи·ҹдёҮз»ҙзҪ‘пјҲWorld Wide Webпјүе…¶е®һзӣёе·®ж— еҮ пјҢеҗҺиҖ…е°ұжҳҜдёҖдёӘи¶…еӨ§зҡ„гҖҒй«ҳеәҰж··д№ұзҡ„д»Ҙеҗ„з§ҚеҪўејҸеӯҳж”ҫзҡ„ж–Ү件е ҶгҖӮеҪ“然пјҢд»ҺдёҮз»ҙзҪ‘дёӯжүҫдҝЎжҒҜжҲ‘们жңүеҠһжі•и§ЈеҶіпјҢеӣ дёәжҲ‘们еҜ№жҗңзҙўеј•ж“ҺйқһеёёзҶҹжӮүпјҲжҲ–и®ёдҪ е°ұжҳҜйҖҡиҝҮжҗңзҙўжүҫеҲ°иҝҷзҜҮж–Үз« зҡ„пјүгҖӮжң¬ж–Үе°Ҷд»Ӣз»Қи°·жӯҢзҡ„зҪ‘йЎөжҺ’еәҸз®—жі•пјҲPageRank AlgorithmпјүпјҢд»ҘеҸҠе®ғеҰӮдҪ•д»Һ250дәҝд»ҪзҪ‘йЎөдёӯжҚһеҲ°дёҺдҪ зҡ„жҗңзҙўжқЎд»¶еҢ№й…Қзҡ„з»“жһңгҖӮе®ғзҡ„еҢ№й…Қж•ҲжһңеҰӮжӯӨд№ӢеҘҪпјҢд»ҘиҮідәҺвҖңи°·жӯҢвҖқпјҲgoogleпјүд»ҠеӨ©е·Із»ҸжҲҗдёәдёҖдёӘиў«е№ҝжіӣдҪҝз”Ёзҡ„еҠЁиҜҚдәҶгҖӮ
еҢ…жӢ¬и°·жӯҢеңЁеҶ…пјҢеӨҡж•°жҗңзҙўеј•ж“ҺйғҪжҳҜдёҚж–ӯең°иҝҗиЎҢи®Ўз®—жңәзЁӢеәҸзҫӨпјҢжқҘжЈҖзҙўзҪ‘з»ңдёҠзҡ„зҪ‘йЎөгҖҒжҗңзҙўжҜҸд»Ҫж–Ү件дёӯзҡ„иҜҚиҜӯ并且е°Ҷзӣёе…ідҝЎжҒҜд»Ҙй«ҳж•Ҳзҡ„еҪўејҸиҝӣиЎҢеӯҳеӮЁгҖӮжҜҸеҪ“з”ЁжҲ·жЈҖзҙўдёҖдёӘзҹӯиҜӯпјҢдҫӢеҰӮвҖңжҗңзҙўеј•ж“ҺвҖқпјҢжҗңзҙўеј•ж“Һе°ұе°ҶжүҫеҮәжүҖжңүеҗ«жңүиў«жЈҖзҙўзҹӯиҜӯзҡ„зҪ‘йЎөгҖӮпјҲжҲ–и®ёпјҢзұ»дјјвҖңжҗңзҙўвҖқдёҺвҖңеј•ж“ҺвҖқд№Ӣй—ҙзҡ„и·қзҰ»иҝҷж ·зҡ„йўқеӨ–дҝЎжҒҜйғҪиў«дјҡиҖғиҷ‘еңЁеҶ…гҖӮпјүдҪҶй—®йўҳжҳҜпјҢи°·жӯҢзҺ°еңЁйңҖиҰҒжЈҖзҙў250дәҝдёӘйЎөйқўпјҢиҖҢиҝҷдәӣйЎөйқўдёҠеӨ§зәҰ95%зҡ„ж–Үжң¬д»…з”ұеӨ§зәҰдёҖдёҮдёӘеҚ•иҜҚз»„жҲҗгҖӮд№ҹе°ұжҳҜиҜҙпјҢеҜ№дәҺеӨ§еӨҡж•°жҗңзҙўиҖҢиЁҖпјҢе°Ҷдјҡжңүи¶…зә§еӨҡзҡ„зҪ‘йЎөеҗ«жңүжҗңзҙўзҹӯиҜӯдёӯзҡ„еҚ•иҜҚгҖӮжҲ‘们жүҖйңҖиҰҒзҡ„е…¶е®һжҳҜиҝҷж ·дёҖз§ҚеҠһжі•пјҢе®ғиғҪеӨҹе°Ҷиҝҷдәӣз¬ҰеҗҲжҗңзҙўжқЎд»¶зҡ„зҪ‘йЎөжҢүз…§йҮҚиҰҒзЁӢеәҰиҝӣиЎҢжҺ’еәҸпјҢиҝҷж ·жүҚиғҪеӨҹе°ҶжңҖйҮҚиҰҒзҡ„йЎөйқўжҺ’еңЁжңҖдёҠйқўгҖӮ
зЎ®е®ҡзҪ‘йЎөйҮҚиҰҒжҖ§зҡ„дёҖдёӘж–№жі•жҳҜдҪҝз”ЁдәәдёәжҺ’еәҸгҖӮдҫӢеҰӮпјҢдҪ жҲ–и®ёи§ҒиҝҮиҝҷж ·дёҖдәӣзҪ‘йЎөпјҢ他们еҢ…еҗ«дәҶеӨ§йҮҸзҡ„й“ҫжҺҘпјҢеҗҺиҖ…иҝһжҺҘеҲ°жҹҗдёӘзү№е®ҡе…ҙи¶ЈйўҶеҹҹзҡ„е…¶д»–иө„жәҗгҖӮеҒҮе®ҡз»ҙжҠӨиҝҷдёӘзҪ‘йЎөзҡ„дәәжҳҜеҸҜйқ зҡ„пјҢйӮЈд№Ҳд»–жҺЁиҚҗзҡ„зҪ‘йЎөеңЁеҫҲеӨ§зЁӢеәҰдёҠе°ұеҸҜиғҪжңүз”ЁгҖӮеҪ“然пјҢиҝҷз§ҚеҒҡжі•д№ҹжңүе…¶еұҖйҷҗжҖ§пјҢжҜ”еҰӮиҝҷдёӘеҲ—иЎЁеҸҜиғҪеҫҲеҝ«е°ұиҝҮжңҹдәҶпјҢд№ҹеҸҜиғҪз»ҙжҠӨиҝҷдёӘеҲ—иЎЁзҡ„дәәдјҡж— ж„ҸжҲ–еӣ жҹҗз§ҚжңӘзҹҘзҡ„еҒҸи§ҒиҖҢйҒ—жјҸжҺүдёҖдәӣйҮҚиҰҒзҡ„зҪ‘йЎөгҖӮ
и°·жӯҢзҡ„зҪ‘йЎөжҺ’еәҸз®—жі•еҲҷдёҚеҖҹеҠ©дәәдёәзҡ„еҶ…е®№иҜ„дј°жқҘзЎ®е®ҡзҪ‘йЎөзҡ„йҮҚиҰҒжҖ§гҖӮдәӢе®һдёҠпјҢи°·жӯҢеҸ‘зҺ°пјҢе®ғзҡ„жңҚеҠЎзҡ„д»·еҖјеҫҲеӨ§зЁӢеәҰдёҠжҳҜе®ғиғҪеӨҹжҸҗдҫӣз»ҷз”ЁжҲ·ж— еҒҸи§Ғзҡ„жҗңзҙўз»“жһңгҖӮи°·жӯҢеЈ°з§°пјҢвҖңжҲ‘们иҪҜ件зҡ„ж ёеҝғе°ұжҳҜзҪ‘йЎөжҺ’еәҸпјҲPageRankпјүгҖӮвҖқжӯЈеҰӮжҲ‘们е°ҶиҰҒзңӢеҲ°зҡ„пјҢжҠҖе·§е°ұжҳҜи®©зҪ‘йЎөиҮӘиә«жҢүз…§йҮҚиҰҒжҖ§иҝӣиЎҢжҺ’еәҸгҖӮ
1гҖҒеҰӮдҪ•иҫЁеҲ«и°ҒйҮҚиҰҒпјҹ
еҰӮжһңдҪ жӣҫе»әз«ӢиҝҮдёҖдёӘзҪ‘йЎөпјҢдҪ еә”иҜҘдјҡеҲ—е…ҘдёҖдәӣдҪ ж„ҹе…ҙи¶Јзҡ„й“ҫжҺҘпјҢе®ғ们еҫҲе®№жҳ“дҪҝдҪ зӮ№еҮ»еҲ°е…¶е®ғеҗ«жңүйҮҚиҰҒгҖҒеҸҜйқ дҝЎжҒҜзҡ„зҪ‘йЎөгҖӮиҝҷж ·е°ұзӣёеҪ“дәҺдҪ иӮҜе®ҡдәҶдҪ жүҖй“ҫжҺҘйЎөйқўзҡ„йҮҚиҰҒжҖ§гҖӮи°·жӯҢзҡ„зҪ‘йЎөжҺ’еәҸз®—жі•жҜҸжңҲеңЁжүҖжңүзҪ‘йЎөдёӯиҝӣиЎҢдёҖж¬ЎеҸ—ж¬ўиҝҺзЁӢеәҰзҡ„иҜ„дј°пјҢд»ҘзЎ®е®ҡе“ӘдәӣзҪ‘йЎөжңҖйҮҚиҰҒгҖӮзҪ‘йЎөжҺ’еәҸз®—жі•зҡ„жҸҗеҮәиҖ…пјҢи°ўе°”зӣ–вҖўеёғжһ—(Sergey Brin)е’ҢжӢүйҮҢвҖўдҪ©еҘҮ(Lawrence Page)зҡ„еҹәжң¬жғіжі•жҳҜпјҡдёҖдёӘзҪ‘йЎөзҡ„йҮҚиҰҒжҖ§жҳҜз”ұй“ҫжҺҘеҲ°е®ғзҡ„е…¶д»–зҪ‘йЎөзҡ„ж•°йҮҸеҸҠе…¶йҮҚиҰҒжҖ§жқҘеҶіе®ҡгҖӮ
жҲ‘们еҜ№д»»ж„ҸдёҖдёӘзҪ‘йЎөPпјҢд»ҘI(P)жқҘиЎЁиҝ°е…¶йҮҚиҰҒжҖ§пјҢ并称д№ӢдёәзҪ‘йЎөзҡ„зҪ‘йЎөжҺ’еәҸгҖӮеңЁеҫҲеӨҡзҪ‘з«ҷпјҢдҪ еҸҜд»ҘжүҫеҲ°дёҖдёӘиҝ‘дјјзҡ„зҪ‘йЎөжҺ’еәҸеҖјгҖӮпјҲдҫӢеҰӮпјҢзҫҺеӣҪж•°еӯҰдјҡзҡ„йҰ–йЎөзӣ®еүҚзҡ„зҪ‘йЎөжҺ’еәҸеҖјдёә8пјҢжңҖй«ҳеҲҶжҳҜ10гҖӮдҪ еҸҜд»ҘиҜ•иҜ•жүҫеҲ°дёҖдёӘзҪ‘йЎөжҺ’еәҸеҖјдёә10зҡ„зҪ‘йЎөеҗ—пјҹпјүиҝҷдёӘзҪ‘йЎөжҺ’еәҸеҖјд»…жҳҜдёҖдёӘиҝ‘дјјеҖјпјҢеӣ дёәи°·жӯҢжӢ’з»қжҸҗдҫӣзңҹе®һзҡ„зҪ‘йЎөжҺ’еәҸеҖјпјҢд»Ҙйҳ»жӯўйӮЈдәӣиҜ•еӣҫе№Іжү°жҺ’еәҸзҡ„иЎҢдёәгҖӮ
зҪ‘йЎөжҺ’еәҸжҳҜиҝҷж ·зЎ®е®ҡзҡ„гҖӮеҒҮе®ҡзҪ‘йЎөPj жңүlj дёӘй“ҫжҺҘгҖӮеҰӮжһңиҝҷдәӣй“ҫжҺҘдёӯзҡ„дёҖдёӘй“ҫжҺҘеҲ°зҪ‘йЎөPiпјҢйӮЈд№ҲзҪ‘йЎөPj е°Ҷдјҡе°Ҷе…¶йҮҚиҰҒжҖ§зҡ„1/lj иөӢз»ҷPiгҖӮзҪ‘йЎөPi зҡ„йҮҚиҰҒжҖ§е°ұжҳҜжүҖжңүжҢҮеҗ‘иҝҷдёӘзҪ‘йЎөзҡ„е…¶д»–зҪ‘йЎөжүҖиҙЎзҢ®зҡ„йҮҚиҰҒжҖ§зҡ„еҠ е’ҢгҖӮжҚўиЁҖд№ӢпјҢеҰӮжһңжҲ‘们记й“ҫжҺҘеҲ°зҪ‘йЎөPi зҡ„зҪ‘йЎөйӣҶеҗҲдёәBiпјҢйӮЈд№Ҳ
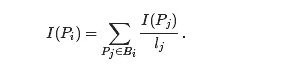
иҝҷжҲ–и®ёи®©дҪ жғіиө·вҖңе…ҲжңүйёЎиҝҳжҳҜе…ҲжңүиӣӢвҖқзҡ„й—®йўҳпјҡдёәдәҶзЎ®е®ҡдёҖдёӘзҪ‘йЎөзҡ„йҮҚиҰҒжҖ§пјҢжҲ‘们йҰ–е…Ҳеҫ—зҹҘйҒ“жүҖжңүжҢҮеҗ‘е®ғзҡ„е…¶д»–зҪ‘йЎөзҡ„йҮҚиҰҒжҖ§гҖӮ然иҖҢпјҢжҲ‘们еҸҜе°ҶиҝҷдёӘй—®йўҳж”№еҶҷдёәдёҖдёӘжӣҙж•°еӯҰеҢ–зҡ„й—®йўҳгҖӮ
йҰ–е…Ҳе»әз«ӢдёҖдёӘзҹ©йҳөпјҢз§°дёәи¶…й“ҫзҹ©йҳөпјҲhyperlink matrixпјүпјҢH=[Hij ]пјҢе…¶дёӯ第i иЎҢ第j еҲ—зҡ„е…ғзҙ дёә

жіЁж„ҸеҲ°HжңүдёҖдәӣзү№ж®Ҡзҡ„жҖ§иҙЁгҖӮйҰ–е…ҲпјҢе®ғжүҖжңүзҡ„е…ғйғҪжҳҜйқһиҙҹзҡ„гҖӮе…¶ж¬ЎпјҢйҷӨйқһеҜ№еә”иҝҷдёҖеҲ—зҡ„зҪ‘йЎөжІЎжңүд»»дҪ•й“ҫжҺҘпјҢе®ғзҡ„жҜҸдёҖеҲ—зҡ„е’Ңдёә1гҖӮжүҖжңүе…ғеқҮйқһиҙҹдё”еҲ—е’Ңдёә1зҡ„зҹ©йҳөз§°дёәйҡҸжңәзҹ©йҳөпјҢйҡҸжңәзҹ©йҳөе°ҶеңЁдёӢиҝ°еҶ…е®№дёӯиө·еҲ°йҮҚиҰҒдҪңз”ЁгҖӮ
жҲ‘们иҝҳйңҖиҰҒе®ҡд№үеҗ‘йҮҸI=[I (Pi )]пјҢе®ғзҡ„е…ғзҙ дёәжүҖжңүзҪ‘йЎөзҡ„зҪ‘йЎөжҺ’еәҸвҖ”вҖ”йҮҚиҰҒжҖ§зҡ„жҺ’еәҸеҖјгҖӮеүҚйқўе®ҡд№үзҡ„зҪ‘йЎөжҺ’еәҸеҸҜд»ҘиЎЁиҝ°дёә
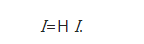
жҚўиЁҖд№ӢпјҢеҗ‘йҮҸIжҳҜзҹ©йҳөHеҜ№еә”зү№еҫҒеҖј1зҡ„зү№еҫҒеҗ‘йҮҸгҖӮжҲ‘们д№ҹз§°д№Ӣдёәзҹ©йҳөHзҡ„е№ізЁіеҗ‘йҮҸпјҲstationaryvectorпјүгҖӮ
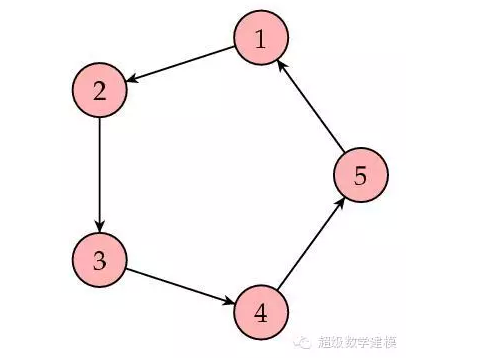
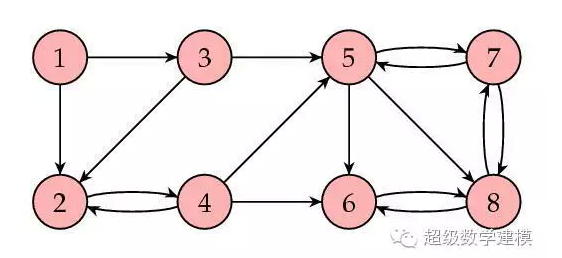
и®©жҲ‘们жқҘзңӢдёҖдёӘдҫӢеӯҗгҖӮдёӢеӣҫжүҖзӨәдёәдёҖдёӘзҪ‘йЎөйӣҶеҗҲпјҲ8дёӘпјүпјҢз®ӯеӨҙиЎЁзӨәй“ҫжҺҘгҖӮ
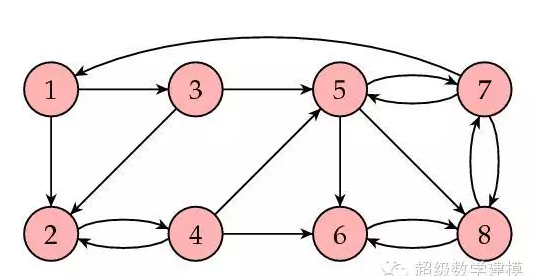
е…¶зӣёеә”зҡ„зҹ©йҳөдёә

иҝҷиҜҙжҳҺзҪ‘йЎө8зҡ„еҸ—ж¬ўиҝҺзЁӢеәҰжңҖй«ҳгҖӮдёӢеӣҫжҳҜйҳҙеҪұеҢ–зҡ„еӣҫпјҢе…¶дёӯзҪ‘йЎөжҺ’еәҸеҖји¶Ҡй«ҳзҡ„зҪ‘йЎөйҳҙеҪұи¶Ҡжө…гҖӮ
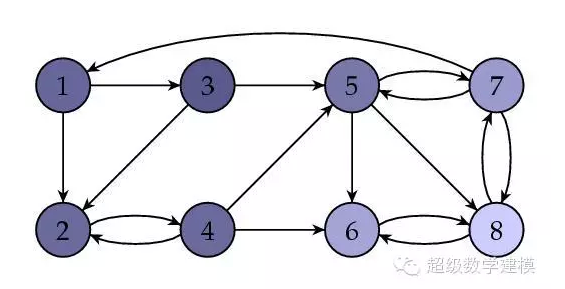
2гҖҒи®Ўз®—е№ізЁіеҗ‘йҮҸI
жңүеҫҲеӨҡж–№жі•еҸҜд»ҘжүҫеҲ°дёҖдёӘж–№йҳөзҡ„зү№еҫҒеҗ‘йҮҸгҖӮ然иҖҢпјҢжҲ‘们йқўеҜ№зҡ„жҳҜдёҖдёӘзү№ж®Ҡзҡ„жҢ‘жҲҳпјҢеӣ дёәзҹ©йҳөHжҳҜдёҖдёӘиҝҷж ·зҡ„ж–№йҳөпјҢе®ғзҡ„жҜҸдёҖеҲ—йғҪеҜ№еә”и°·жӯҢжЈҖзҙўеҲ°зҡ„дёҖдёӘзҪ‘йЎөгҖӮд№ҹе°ұжҳҜиҜҙпјҢHеӨ§зәҰжңүn=250дәҝиЎҢе’ҢеҲ—гҖӮдёҚиҝҮе…¶дёӯеӨ§еӨҡж•°зҡ„е…ғйғҪжҳҜ0пјӣдәӢе®һдёҠпјҢз ”з©¶иЎЁжҳҺжҜҸдёӘзҪ‘йЎөе№іеқҮзәҰжңү10дёӘй“ҫжҺҘпјҢжҚўиЁҖд№ӢпјҢе№іеқҮиҖҢиЁҖпјҢжҜҸдёҖеҲ—дёӯйҷӨдәҶ10дёӘе…ғеӨ–е…ЁжҳҜ0гҖӮжҲ‘们е°ҶйҖүжӢ©иў«з§°дёәе№Ӯжі•пјҲpowermethodпјүзҡ„ж–№жі•жқҘжүҫеҲ°зҹ©йҳөHзҡ„е№ізЁіеҗ‘йҮҸIгҖӮ
е№Ӯжі•еҰӮдҪ•е®һзҺ°е‘ўпјҹйҰ–е…ҲйҖүжӢ©Iзҡ„еӨҮйҖүеҗ‘йҮҸI^0пјҢиҝӣиҖҢжҢүдёӢејҸдә§з”ҹеҗ‘йҮҸеәҸеҲ—I^k
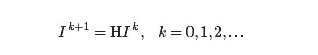
иҝҷдёӘж–№жі•жҳҜе»әз«ӢеңЁеҰӮдёӢзҡ„дёҖиҲ¬еҺҹзҗҶдёҠпјҡ
дёҖиҲ¬еҺҹзҗҶпјҡеәҸеҲ—Ik е°Ҷ收ж•ӣеҲ°е№ізЁіеҗ‘йҮҸIгҖӮ
жҲ‘们йҰ–е…Ҳз”ЁдёӘдҫӢеӯҗйӘҢиҜҒдёҠйқўзҡ„з»“и®әгҖӮ
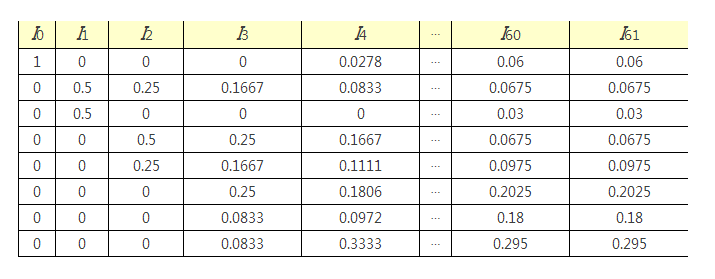
дёҖдёӘиҮӘ然зҡ„й—®йўҳжҳҜпјҢиҝҷдәӣж•°еӯ—жңүд»Җд№Ҳеҗ«д№үгҖӮеҪ“然пјҢе…ідәҺдёҖдёӘзҪ‘йЎөзҡ„йҮҚиҰҒжҖ§пјҢеҸҜиғҪжІЎжңүз»қеҜ№зҡ„еәҰйҮҸпјҢиҖҢд»…жңүжҜ”иҫғдёӨдёӘзҪ‘йЎөзҡ„йҮҚиҰҒжҖ§зҡ„жҜ”дҫӢеәҰйҮҸпјҢеҰӮвҖңзҪ‘йЎөAзҡ„йҮҚиҰҒжҖ§жҳҜзҪ‘йЎөBзҡ„дёӨеҖҚгҖӮвҖқеҹәдәҺиҝҷдёҖеҺҹеӣ пјҢжҲ‘们еҸҜд»Ҙз”ЁдёҖдёӘеӣәе®ҡйҮҸеҺ»еҗҢд№ҳд»ҘжүҖжңүзҡ„йҮҚиҰҒжҖ§жҺ’еәҸеҖјпјҢиҝҷ并дёҚдјҡеҪұе“ҚжҲ‘们иғҪиҺ·еҫ—зҡ„дҝЎжҒҜгҖӮиҝҷж ·пјҢжҲ‘们жҖ»жҳҜеҒҮе®ҡжүҖжңүеҸ—ж¬ўиҝҺзЁӢеәҰеҖјпјҲpopularityпјүзҡ„е’Ңдёә1пјҢеҺҹеӣ зЁҚеҗҺи§ЈйҮҠгҖӮ
3гҖҒдёүдёӘйҮҚиҰҒзҡ„й—®йўҳ
иҮӘ然иҖҢ然дә§з”ҹзҡ„дёүдёӘй—®йўҳжҳҜпјҡ
В· В В В еәҸеҲ—I^kжҖ»жҳҜ收ж•ӣеҗ—пјҹпјҲеҚіиҝҗз®—еӨҡж¬ЎеҗҺпјҢI^kе’ҢI^(k+1)еҮ д№ҺжҳҜдёҖж ·зҡ„пјү
В·    收ж•ӣеҗҺзҡ„е№ізЁіеҗ‘йҮҸжҳҜеҗҰе’ҢеҲқе§Ӣеҗ‘йҮҸI^0зҡ„йҖүеҸ–жІЎжңүе…ізі»пјҹ
В· В В В йҮҚиҰҒжҖ§жҺ’еәҸеҖјжҳҜеҗҰеҢ…еҗ«дәҶжҲ‘们жғіиҰҒзҡ„дҝЎжҒҜпјҹ
еҜ№зӣ®еүҚзҡ„ж–№жі•иҖҢиЁҖпјҢдёҠиҝ°дёүдёӘзҡ„зӯ”жЎҲйғҪжҳҜеҗҰе®ҡзҡ„пјҒдёӢйқўпјҢжҲ‘们е°ҶзңӢзңӢеҰӮдҪ•ж”№иҝӣжҲ‘们зҡ„ж–№жі•пјҢдҪҝеҫ—ж”№иҝӣеҗҺзҡ„з®—жі•ж»Ўи¶ідёҠиҝ°дёүдёӘиҰҒжұӮгҖӮ
е…ҲзңӢдёӘйқһеёёз®ҖеҚ•зҡ„дҫӢеӯҗгҖӮиҖғиҷ‘еҰӮдёӢеҢ…еҗ«дёӨдёӘзҪ‘йЎөзҡ„е°ҸзҪ‘з»ңпјҢе…¶дёӯдёҖдёӘй“ҫжҺҘеҲ°еҸҰдёҖдёӘпјҡ

дёӢдҫӢеұ•зӨәдәҶз®—жі•зҡ„иҝҗиЎҢиҝҮзЁӢпјҡ

еңЁиҝҷдёӘдҫӢеӯҗдёӯпјҢдёӨдёӘзҪ‘йЎөзҡ„йҮҚиҰҒжҖ§жҺ’еәҸеҖјеқҮдёә0пјҢиҝҷж ·жҲ‘д»¬ж— жі•иҺ·зҹҘдёӨдёӘзҪ‘йЎөд№Ӣй—ҙзҡ„зӣёеҜ№йҮҚиҰҒжҖ§дҝЎжҒҜгҖӮй—®йўҳеңЁдәҺзҪ‘йЎөP2 жІЎжңүд»»дҪ•й“ҫжҺҘгҖӮеӣ жӯӨпјҢеңЁжҜҸдёӘиҝӯд»ЈжӯҘйӘӨдёӯпјҢе®ғд»ҺзҪ‘йЎөP1 иҺ·еҸ–дәҶдёҖдәӣйҮҚиҰҒжҖ§пјҢдҪҶеҚҙжІЎжңүиөӢз»ҷе…¶д»–д»»дҪ•зҪ‘йЎөгҖӮиҝҷж ·е°ҶиҖ—е°ҪзҪ‘з»ңдёӯзҡ„жүҖжңүйҮҚиҰҒжҖ§гҖӮжІЎжңүд»»дҪ•й“ҫжҺҘзҡ„зҪ‘йЎөз§°дёәжӮ¬жҢӮзӮ№пјҲdangling nodesпјүпјҢжҳҫ然еңЁжҲ‘们иҰҒз ”з©¶зҡ„е®һйҷ…зҪ‘з»ңдёӯеӯҳеңЁеҫҲеӨҡиҝҷж ·зҡ„зӮ№гҖӮзЁҚеҗҺжҲ‘们е°ҶзңӢеҲ°еҰӮдҪ•еӨ„зҗҶиҝҷж ·зҡ„зӮ№пјҢеңЁжӯӨд№ӢеүҚжҲ‘们е…ҲиҖғиҷ‘дёҖз§Қж–°зҡ„зҗҶи§Јзҹ©йҳөHе’Ңе№ізЁіеҗ‘йҮҸI зҡ„жҖқи·ҜгҖӮ
4гҖҒHзҡ„жҰӮзҺҮеҢ–и§ЈйҮҠ
жғіиұЎжҲ‘们йҡҸжңәең°еңЁзҪ‘дёҠи·іиҪ¬зҪ‘йЎөпјӣд№ҹе°ұжҳҜиҜҙпјҢеҪ“жҲ‘们и®ҝй—®дёҖдёӘзҪ‘йЎөж—¶пјҢдёҖз§’й’ҹеҗҺжҲ‘们йҡҸжңәең°йҖүжӢ©еҪ“еүҚзҪ‘йЎөзҡ„дёҖдёӘй“ҫжҺҘеҲ°иҫҫеҸҰдёҖдёӘзҪ‘йЎөгҖӮдҫӢеҰӮпјҢжҲ‘们жӯЈи®ҝй—®еҗ«жңүlj дёӘй“ҫжҺҘзҡ„зҪ‘йЎөPjпјҢе…¶дёӯдёҖдёӘй“ҫжҺҘеј•еҜјжҲ‘们и®ҝй—®дәҶзҪ‘йЎөPiпјҢйӮЈд№ҲдёӢдёҖжӯҘиҪ¬еҲ°зҪ‘йЎөPi зҡ„жҰӮзҺҮе°ұжҳҜ1/lj гҖӮ
з”ұдәҺи·іиҪ¬зҪ‘йЎөжҳҜйҡҸжңәзҡ„пјҢжҲ‘们用TjиЎЁзӨәеҒңз•ҷеңЁзҪ‘йЎөPj дёҠзҡ„ж—¶й—ҙгҖӮйӮЈд№ҲжҲ‘们д»ҺзҪ‘йЎөPj иҪ¬еҲ°зҪ‘йЎөPi зҡ„ж—¶й—ҙдёәTj /lj В гҖӮеҰӮжһңжҲ‘们иҪ¬еҲ°дәҶзҪ‘йЎөPiпјҢйӮЈд№ҲжҲ‘们еҝ…然жҳҜд»ҺдёҖдёӘжҢҮеҗ‘е®ғзҡ„зҪ‘йЎөиҖҢжқҘгҖӮиҝҷж„Ҹе‘ізқҖ

е…¶дёӯжұӮе’ҢжҳҜеҜ№жүҖжңүй“ҫжҺҘеҲ°Pi зҡ„зҪ‘йЎөPj иҝӣиЎҢзҡ„гҖӮжіЁж„ҸеҲ°иҝҷдёӘж–№зЁӢдёҺе®ҡд№үзҪ‘йЎөжҺ’еәҸеҖјзҡ„ж–№зЁӢзӣёеҗҢпјҢеӣ жӯӨI (Pi )=TiгҖӮйӮЈд№ҲдёҖдёӘзҪ‘йЎөзҡ„зҪ‘йЎөжҺ’еәҸеҖјеҸҜд»Ҙи§ЈйҮҠдёәйҡҸжңәи·іиҪ¬ж—¶иҠұеңЁиҝҷдёӘзҪ‘йЎөдёҠзҡ„ж—¶й—ҙгҖӮеҰӮжһңдҪ жӣҫз»ҸдёҠзҪ‘жөҸи§ҲиҝҮжҹҗдёӘдҪ дёҚзҶҹжӮүзҡ„иҜқйўҳзҡ„зӣёе…ідҝЎжҒҜж—¶пјҢдҪ дјҡжңүиҝҷз§Қж„ҹи§үпјҡжҢүз…§й“ҫжҺҘи·іиҪ¬зҪ‘йЎөпјҢиҝҮдёҖдјҡдҪ дјҡеҸ‘зҺ°пјҢзӣёиҫғдәҺе…¶д»–зҪ‘йЎөпјҢдҪ дјҡжӣҙйў‘з№Ғең°еӣһеҲ°жҹҗдёҖйғЁеҲҶзҪ‘йЎөгҖӮжӯЈеҰӮи°ҡиҜӯжүҖиҜҙвҖңжқЎжқЎеӨ§и·ҜйҖҡзҪ—马пјҢвҖқиҝҷйғЁеҲҶзҪ‘йЎөжҳҫ然жҳҜжӣҙйҮҚиҰҒзҡ„зҪ‘йЎөгҖӮ
еҹәдәҺиҝҷдёӘи§ЈйҮҠпјҢеҫҲиҮӘ然ең°еҸҜд»ҘиҰҒжұӮзҪ‘йЎөжҺ’еәҸеҗ‘йҮҸI зҡ„жүҖжңүе…ғд№Ӣе’Ңдёә1гҖӮ
еҪ“然пјҢиҝҷз§ҚиЎЁиҝ°дёӯиҝҳеӯҳеңЁдёҖдёӘй—®йўҳпјҡеҰӮжһңжҲ‘们йҡҸжңәең°и·іиҪ¬зҪ‘йЎөпјҢеңЁжҹҗз§ҚзЁӢеәҰдёҠпјҢжҲ‘们иӮҜе®ҡдјҡиў«еӣ°еңЁжҹҗдёӘжӮ¬жҢӮзӮ№дёҠпјҢиҝҷдёӘзҪ‘йЎөжІЎжңүз»ҷеҮәд»»дҪ•й“ҫжҺҘгҖӮдёәдәҶиғҪеӨҹ继з»ӯиҝӣиЎҢпјҢжҲ‘们йңҖиҰҒйҡҸжңәең°йҖүеҸ–дёӢдёҖдёӘзҪ‘йЎөпјӣд№ҹе°ұжҳҜиҜҙпјҢжҲ‘们еҒҮе®ҡжӮ¬жҢӮзӮ№еҸҜд»Ҙй“ҫжҺҘеҲ°е…¶д»–д»»дҪ•дёҖдёӘзҪ‘йЎөгҖӮиҝҷдёӘж•ҲжһңзӣёеҪ“дәҺе°Ҷи¶…й“ҫзҹ©йҳөHеҒҡеҰӮдёӢдҝ®жӯЈпјҡе°Ҷе…¶дёӯжүҖжңүе…ғйғҪдёә0зҡ„еҲ—жӣҝжҚўдёәжүҖжңүе…ғеқҮдёә1/nзҡ„еҲ—пјҢеүҚиҖ…е°ұеҜ№еә”дәҺзҪ‘йЎөдёӯзҡ„жӮ¬жҢӮзӮ№гҖӮиҝҷж ·дҝ®жӯЈеҗҺжӮ¬жҢӮзӮ№е°ұдёҚеӯҳеңЁдәҶгҖӮжҲ‘们称дҝ®жӯЈеҗҺзҡ„ж–°зҹ©йҳөдёәSгҖӮ
жҲ‘们д№ӢеүҚзҡ„дҫӢеӯҗпјҢзҺ°еңЁе°ұеҸҳжҲҗдәҶ
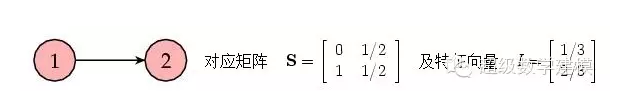
жҚўиЁҖд№ӢпјҢзҪ‘йЎөP2зҡ„йҮҚиҰҒжҖ§жҳҜзҪ‘йЎөP1 зҡ„дёӨеҖҚпјҢз¬ҰеҗҲдҪ зҡ„зӣҙи§Ӯи®ӨзҹҘдәҶгҖӮ
зҹ©йҳөSжңүдёҖдёӘеҫҲеҘҪзҡ„жҖ§иҙЁпјҢеҚіе…¶жүҖжңүе…ғеқҮйқһиҙҹдё”жҜҸеҲ—зҡ„е’ҢеқҮдёә1гҖӮжҚўиЁҖд№ӢпјҢSдёәйҡҸжңәзҹ©йҳөгҖӮйҡҸжңәзҹ©йҳөе…·жңүдёҖдәӣеҫҲжңүз”Ёзҡ„жҖ§иҙЁгҖӮдҫӢеҰӮпјҢйҡҸжңәзҹ©йҳөжҖ»жҳҜеӯҳеңЁе№ізЁіеҗ‘йҮҸгҖӮ
дёәдәҶзЁҚеҗҺзҡ„еә”з”ЁпјҢжҲ‘们иҰҒжіЁж„ҸеҲ°SжҳҜз”ұHйҖҡиҝҮдёҖдёӘз®ҖеҚ•зҡ„дҝ®жӯЈеҫ—еҲ°гҖӮе®ҡд№үзҹ©йҳөAеҰӮдёӢпјҡеҜ№еә”дәҺжӮ¬жҢӮзӮ№зҡ„еҲ—зҡ„жҜҸдёӘе…ғеқҮдёә1/nпјҢе…¶дҪҷеҗ„е…ғеқҮдёә0гҖӮеҲҷS=H+AгҖӮ
5гҖҒе№Ӯжі•еҰӮдҪ•е®һзҺ°пјҹ
дёҖиҲ¬иҖҢиЁҖпјҢе№Ӯжі•жҳҜеҜ»жүҫзҹ©йҳөеҜ№еә”дәҺз»қеҜ№еҖјжңҖеӨ§зҡ„зү№еҫҒеҖјзҡ„зү№еҫҒеҗ‘йҮҸгҖӮе°ұжҲ‘们иҖҢиЁҖпјҢжҲ‘们иҰҒеҜ»жүҫзҹ©йҳөSеҜ№еә”дәҺзү№еҫҒеҖј1зҡ„зү№еҫҒеҗ‘йҮҸгҖӮйҰ–е…ҲиҰҒиҜҙеҲ°зҡ„жҳҜжңҖеҘҪзҡ„жғ…еҪўгҖӮеңЁиҝҷз§Қжғ…еҪўдёӢпјҢе…¶д»–зү№еҫҒеҖјзҡ„з»қеҜ№еҖјйғҪе°ҸдәҺ1пјӣд№ҹе°ұжҳҜиҜҙпјҢзҹ©йҳөSзҡ„е…¶е®ғзү№еҫҒеҖјйғҪж»Ўи¶і|О»|<1гҖӮ
жҲ‘们еҒҮе®ҡзҹ©йҳөSзҡ„зү№еҫҒеҖјдёәО»j дё”
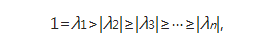
еҜ№зҹ©йҳөSпјҢеҒҮи®ҫеҜ№еә”дәҺзү№еҫҒеҖјО»j зҡ„зү№еҫҒеҗ‘йҮҸеӯҳеңЁдёҖдёӘеҹәеҗ‘йҮҸvj гҖӮиҝҷдёҖеҒҮи®ҫеңЁдёҖиҲ¬жғ…еҶөдёӢ并дёҚдёҖе®ҡиҰҒжҲҗз«ӢпјҢдҪҶеҰӮжһңжҲҗз«ӢеҸҜд»Ҙеё®еҠ©жҲ‘们жӣҙе®№жҳ“ең°зҗҶи§Је№Ӯжі•еҰӮдҪ•е®һзҺ°гҖӮе°ҶеҲқе§Ӣеҗ‘йҮҸI^0еҶҷжҲҗеҰӮдёӢеҪўејҸ
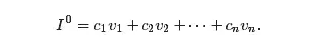
йӮЈд№Ҳ
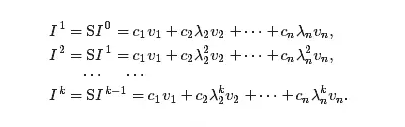
еҪ“jвүҘ2ж—¶пјҢеӣ дёәжүҖжңүзү№еҫҒеҖјзҡ„з»қеҜ№еҖје°ҸдәҺ1пјҢеӣ жӯӨиҝҷжҳҜ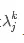 вҶ’0гҖӮд»ҺиҖҢI^kвҶ’I=c1v1пјҢеҗҺиҖ…жҳҜеҜ№еә”дәҺзү№еҫҒеҖј1зҡ„дёҖдёӘзү№еҫҒеҗ‘йҮҸгҖӮ
вҶ’0гҖӮд»ҺиҖҢI^kвҶ’I=c1v1пјҢеҗҺиҖ…жҳҜеҜ№еә”дәҺзү№еҫҒеҖј1зҡ„дёҖдёӘзү№еҫҒеҗ‘йҮҸгҖӮ
вҶ’0гҖӮд»ҺиҖҢI^kвҶ’I=c1v1пјҢеҗҺиҖ…жҳҜеҜ№еә”дәҺзү№еҫҒеҖј1зҡ„дёҖдёӘзү№еҫҒеҗ‘йҮҸгҖӮйңҖиҰҒжҢҮеҮәзҡ„жҳҜпјҢI^kвҶ’I зҡ„йҖҹеәҰз”ұ|О»2|зЎ®е®ҡгҖӮеҪ“|О»2|жҜ”иҫғжҺҘиҝ‘дәҺ0ж—¶пјҢйӮЈд№Ҳ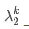 вҶ’0дјҡзӣёеҪ“еҝ«гҖӮдҫӢеҰӮпјҢиҖғиҷ‘дёӢиҝ°зҹ©йҳө
вҶ’0дјҡзӣёеҪ“еҝ«гҖӮдҫӢеҰӮпјҢиҖғиҷ‘дёӢиҝ°зҹ©йҳө
вҶ’0дјҡзӣёеҪ“еҝ«гҖӮдҫӢеҰӮпјҢиҖғиҷ‘дёӢиҝ°зҹ©йҳө
иҝҷдёӘзҹ©йҳөзҡ„зү№еҫҒеҖјдёәО»1=1еҸҠО»2=0.3гҖӮдёӢеӣҫе·ҰеҸҜд»ҘзңӢеҮәз”ЁзәўиүІж Үи®°зҡ„еҗ‘йҮҸI^k 收ж•ӣеҲ°з”Ёз»ҝиүІж Үи®°зҡ„е№ізЁіеҗ‘йҮҸIгҖӮ
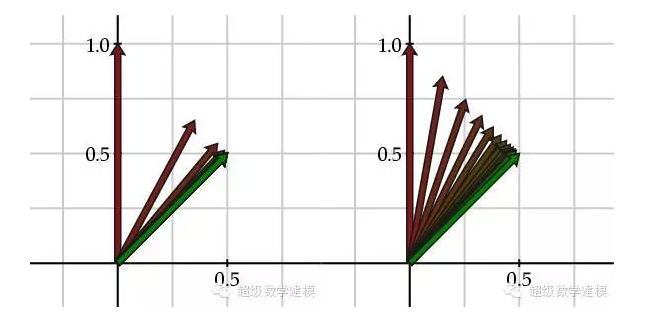
еҶҚиҖғиҷ‘зҹ©йҳө
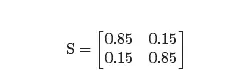
е…¶зү№еҫҒеҖјдёәО»1=1еҸҠО»2=0.7гҖӮд»ҺдёҠеӣҫеҸіеҸҜд»ҘзңӢеҮәпјҢжң¬дҫӢдёӯеҗ‘йҮҸI^k 收ж•ӣеҲ°е№ізЁіеҗ‘йҮҸI зҡ„йҖҹеәҰиҰҒж…ўеҫҲеӨҡпјҢеӣ дёәе®ғзҡ„第дәҢдёӘзү№еҫҒеҖјиҫғеӨ§гҖӮ
6гҖҒдёҚйЎәд№Ӣж—¶
еңЁдёҠиҝ°и®Ёи®әдёӯпјҢжҲ‘们еҒҮе®ҡзҹ©йҳөSйңҖиҰҒж»Ўи¶іО»1=1дё”|О»2|<1гҖӮ然иҖҢпјҢжҲ‘们еҸҜиғҪдјҡеҸ‘зҺ°пјҢиҝҷдёҖзӮ№е№¶дёҚжҖ»жҲҗз«ӢгҖӮ
еҒҮе®ҡзҪ‘з»ңе…ізі»еҰӮдёӢпјҡ
еңЁиҝҷз§Қжғ…еҪўдёӢпјҢзҹ©йҳөSдёә

йӮЈд№ҲжҲ‘们еҸҜд»Ҙеҫ—еҲ°
еңЁиҝҷз§Қжғ…еҶөдёӢпјҢеҗ‘йҮҸеәҸеҲ—I^k дёҚеҶҚ收ж•ӣгҖӮиҝҷжҳҜдёәд»Җд№ҲпјҹжіЁж„ҸеҲ°зҹ©йҳөSзҡ„第дәҢдёӘзү№еҫҒеҖјж»Ўи¶і|О»2|=1пјҢеӣ жӯӨеүҚиҝ°е№Ӯжі•зҡ„еүҚжҸҗдёҚеҶҚжҲҗз«ӢгҖӮ
дёәдәҶдҝқиҜҒ|О»2|<1пјҢжҲ‘们йңҖиҰҒзҹ©йҳөSдёәжң¬еҺҹпјҲprimitiveпјүзҹ©йҳөгҖӮиҝҷж„Ҹе‘ізқҖпјҢеҜ№жҹҗдёӘmпјҢSm зҡ„жүҖжңүе…ғеқҮдёәжӯЈгҖӮжҚўиЁҖд№ӢпјҢиӢҘз»ҷе®ҡдёӨдёӘзҪ‘йЎөпјҢйӮЈд№Ҳд»Һ第дёҖдёӘзҪ‘йЎөз»ҸиҝҮmдёӘй“ҫжҺҘеҗҺеҸҜд»ҘеҲ°иҫҫ第дәҢдёӘзҪ‘йЎөгҖӮжҳҫ然пјҢдёҠиҝ°жңҖеҗҺзҡ„иҝҷдёӘдҫӢеӯҗ并дёҚж»Ўи¶іиҝҷдёӘжқЎд»¶гҖӮзЁҚеҗҺпјҢжҲ‘们е°ҶзңӢеҲ°еҰӮдҪ•дҝ®жӯЈзҹ©йҳөSд»ҘиҺ·еҫ—дёҖдёӘжң¬еҺҹйҡҸжңәзҹ©йҳөпјҢд»ҺиҖҢж»Ўи¶і|О»2|<1гҖӮ
дёӢйқўиҜҙжҳҺжҲ‘们зҡ„ж–№жі•иЎҢдёҚйҖҡзҡ„еҸҰдёҖдёӘдҫӢеӯҗгҖӮиҖғиҷ‘еҰӮдёӢеӣҫжүҖзӨәзҡ„зҪ‘з»ң
еңЁжӯӨдҫӢдёӯпјҢзҹ©йҳөSдёә

жіЁж„ҸеҲ°еүҚеӣӣдёӘзҪ‘йЎөзҡ„зҪ‘йЎөжҺ’еәҸеҖјеқҮдёә0гҖӮиҝҷдҪҝжҲ‘们ж„ҹи§үдёҚеӨӘеҜ№пјҡжҜҸдёӘйЎөйқўйғҪжңүе…¶е®ғзҪ‘йЎөй“ҫжҺҘеҲ°е®ғпјҢжҳҫ然жҖ»жңүдәәе–ңж¬ўиҝҷдәӣзҪ‘йЎөпјҒдёҖиҲ¬жқҘиҜҙпјҢжҲ‘们еёҢжңӣжүҖжңүзҪ‘йЎөзҡ„йҮҚиҰҒжҖ§жҺ’еәҸеҖјеқҮдёәжӯЈгҖӮиҝҷдёӘдҫӢеӯҗзҡ„й—®йўҳеңЁдәҺпјҢе®ғеҢ…еҗ«дәҶдёҖдёӘе°ҸзҪ‘з»ңпјҢеҚідёӢеӣҫдёӯи“қиүІж–№жЎҶйғЁеҲҶгҖӮ
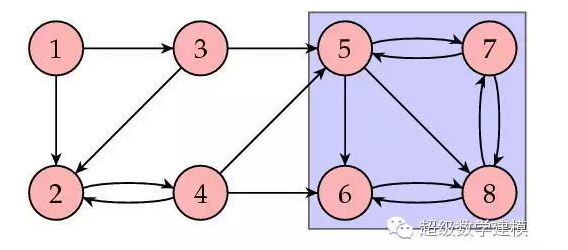
еңЁиҝҷдёӘж–№жЎҶдёӯпјҢжңүй“ҫжҺҘиҝӣе…ҘеҲ°и“қиүІж–№жЎҶпјҢдҪҶжІЎжңүй“ҫжҺҘиҪ¬еҲ°еӨ–йғЁгҖӮжӯЈеҰӮеүҚиҝ°дёӯе…ідәҺжӮ¬жҢӮзӮ№зҡ„дҫӢеӯҗдёҖж ·пјҢиҝҷдәӣзҪ‘йЎөжһ„жҲҗдәҶдёҖдёӘвҖңйҮҚиҰҒжҖ§ж°ҙж§ҪвҖқпјҢе…¶д»–еӣӣдёӘзҪ‘йЎөзҡ„йҮҚиҰҒжҖ§йғҪиў«вҖңжҺ’вҖқеҲ°иҝҷдёӘвҖңж°ҙж§ҪвҖқдёӯгҖӮиҝҷз§Қжғ…еҪўеҸ‘з”ҹеңЁзҹ©йҳөSдёәеҸҜзәҰпјҲreducibleпјүж—¶пјӣд№ҹеҚіпјҢSеҸҜд»ҘеҶҷжҲҗеҰӮдёӢзҡ„еқ—еҪўејҸ
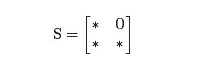
е®һйҷ…дёҠпјҢжҲ‘们еҸҜд»ҘиҜҒжҳҺпјҡеҰӮжһңзҹ©йҳөSдёҚеҸҜзәҰпјҢеҲҷдёҖе®ҡеӯҳеңЁдёҖдёӘжүҖжңүе…ғеқҮдёәжӯЈзҡ„е№ізЁіеҗ‘йҮҸгҖӮ
еҜ№дёҖдёӘзҪ‘з»ңпјҢеҰӮжһңд»»ж„Ҹз»ҷе®ҡдёӨдёӘзҪ‘йЎөпјҢдёҖе®ҡеӯҳеңЁдёҖжқЎз”ұй“ҫжҺҘжһ„жҲҗзҡ„и·ҜдҪҝеҫ—жҲ‘们еҸҜд»Ҙд»Һ第дёҖдёӘзҪ‘йЎөиҪ¬еҲ°з¬¬дәҢдёӘзҪ‘йЎөпјҢйӮЈд№Ҳз§°иҝҷдёӘзҪ‘з»ңжҳҜејәиҝһйҖҡзҡ„пјҲstrongly connectedпјүгҖӮжҳҫ然пјҢдёҠйқўжңҖеҗҺзҡ„иҝҷдёӘдҫӢеӯҗдёҚжҳҜејәиҝһйҖҡзҡ„гҖӮиҖҢејәиҝһйҖҡзҡ„зҪ‘з»ңеҜ№еә”зҡ„зҹ©йҳөSжҳҜдёҚеҸҜзәҰзҡ„гҖӮ
з®ҖиЁҖд№ӢпјҢзҹ©йҳөSжҳҜйҡҸжңәзҹ©йҳөпјҢеҚіж„Ҹе‘ізқҖе®ғжңүдёҖдёӘе№ізЁіеҗ‘йҮҸгҖӮ然иҖҢпјҢжҲ‘们еҗҢж—¶иҝҳйңҖиҰҒSж»Ўи¶і(a)жң¬еҺҹпјҢд»ҺиҖҢ|О»2|<1пјӣ(b)дёҚеҸҜзәҰпјҢд»ҺиҖҢе№ізЁіеҗ‘йҮҸзҡ„жүҖжңүе…ғеқҮдёәжӯЈгҖӮ
7гҖҒжңҖеҗҺдёҖдёӘдҝ®жӯЈ
дёәеҫ—еҲ°дёҖдёӘжң¬еҺҹдё”дёҚеҸҜзәҰзҡ„зҹ©йҳөпјҢжҲ‘们е°Ҷдҝ®жӯЈйҡҸжңәи·іиҪ¬зҪ‘йЎөзҡ„ж–№ејҸгҖӮе°ұзӣ®еүҚжқҘзңӢпјҢжҲ‘们зҡ„йҡҸжңәи·іиҪ¬жЁЎејҸз”ұзҹ©йҳөSзЎ®е®ҡпјҡжҲ–иҖ…жҳҜд»ҺеҪ“еүҚзҪ‘йЎөдёҠзҡ„й“ҫжҺҘдёӯйҖүжӢ©дёҖдёӘпјҢжҲ–иҖ…жҳҜеҜ№жІЎжңүд»»дҪ•й“ҫжҺҘзҡ„зҪ‘йЎөпјҢйҡҸжңәең°йҖүеҸ–е…¶д»–зҪ‘йЎөдёӯзҡ„д»»ж„ҸдёҖдёӘгҖӮдёәдәҶеҒҡеҮәдҝ®жӯЈпјҢйҰ–е…ҲйҖүжӢ©дёҖдёӘд»ӢдәҺ0еҲ°1д№Ӣй—ҙзҡ„еҸӮж•°ОұгҖӮ然еҗҺеҒҮе®ҡйҡҸжңәи·іиҪ¬зҡ„ж–№ејҸз•ҘдҪңеҸҳеҠЁгҖӮе…·дҪ“жҳҜпјҢйҒөеҫӘзҹ©йҳөSзҡ„ж–№ејҸи·іиҪ¬зҡ„жҰӮзҺҮдёәОұпјҢиҖҢйҡҸжңәең°йҖүжӢ©дёӢдёҖдёӘйЎөйқўзҡ„жҰӮзҺҮжҳҜ1вҲ’ОұгҖӮ
иӢҘи®°жүҖжңүе…ғеқҮдёә1зҡ„nГ—n зҹ©йҳөдёәJпјҢйӮЈд№ҲжҲ‘们е°ұеҸҜд»Ҙеҫ—еҲ°и°·жӯҢзҹ©йҳөпјҲGooglematrixпјүпјҡ
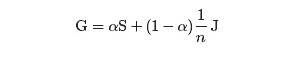
жіЁж„ҸеҲ°GдёәйҡҸжңәзҹ©йҳөпјҢеӣ дёәе®ғжҳҜйҡҸжңәзҹ©йҳөзҡ„з»„еҗҲгҖӮиҝӣиҖҢпјҢзҹ©йҳөGзҡ„жүҖжңүе…ғеқҮдёәжӯЈпјҢеӣ жӯӨGдёәжң¬еҺҹдё”дёҚеҸҜзәҰгҖӮд»ҺиҖҢпјҢGеӯҳеңЁе”ҜдёҖзҡ„е№ізЁіеҗ‘йҮҸIпјҢеҗҺиҖ…еҸҜд»ҘйҖҡиҝҮе№Ӯжі•иҺ·еҫ—гҖӮ
еҸӮж•°Оұ зҡ„дҪңз”ЁжҳҜдёҖдёӘйҮҚиҰҒеӣ зҙ гҖӮиӢҘОұ=1пјҢеҲҷG=SгҖӮиҝҷж„Ҹе‘ізқҖжҲ‘们йқўеҜ№зҡ„жҳҜеҺҹе§Ӣзҡ„зҪ‘з»ңи¶…й“ҫз»“жһ„гҖӮ然иҖҢпјҢиӢҘОұ=0пјҢеҲҷG=1/n JгҖӮд№ҹеҚіжҲ‘们йқўеҜ№зҡ„жҳҜдёҖдёӘд»»ж„ҸдёӨдёӘзҪ‘йЎөд№Ӣй—ҙйғҪжңүиҝһжҺҘзҡ„зҪ‘з»ңпјҢе®ғе·Із»Ҹдё§еӨұдәҶеҺҹе§Ӣзҡ„зҪ‘з»ңи¶…й“ҫз»“жһ„гҖӮжҳҫ然пјҢжҲ‘们е°ҶдјҡжҠҠОұ зҡ„еҖјеҸ–еҫ—жҺҘиҝ‘дәҺ1пјҢд»ҺиҖҢдҝқиҜҒзҪ‘з»ңзҡ„и¶…й“ҫз»“жһ„еңЁи®Ўз®—дёӯзҡ„жқғйҮҚжӣҙеӨ§гҖӮ
然иҖҢпјҢиҝҳжңүеҸҰеӨ–дёҖдёӘй—®йўҳгҖӮиҜ·и®°дҪҸпјҢе№Ӯжі•зҡ„收ж•ӣйҖҹеәҰжҳҜз”ұ第дәҢдёӘзү№еҫҒеҖјзҡ„е№…еҖј|О»2|еҶіе®ҡзҡ„гҖӮиҖҢеҜ№и°·жӯҢзҹ©йҳөпјҢе·Із»ҸиҜҒжҳҺдәҶ第дәҢдёӘзү№еҫҒеҖјзҡ„е№…еҖјдёә|О»2|=ОұгҖӮиҝҷж„Ҹе‘ізқҖеҪ“Оұ жҺҘиҝ‘дәҺ1ж—¶пјҢе№Ӯжі•зҡ„收ж•ӣйҖҹеәҰе°ҶдјҡеҫҲж…ўгҖӮдҪңдёәиҝҷдёӘзҹӣзӣҫзҡ„жҠҳдёӯж–№жЎҲпјҢзҪ‘йЎөжҺ’еәҸз®—жі•зҡ„жҸҗеҮәиҖ…и°ўе°”зӣ–вҖўеёғжһ—е’ҢжӢүйҮҢвҖўдҪ©еҘҮйҖүжӢ© Оұ=0.85гҖӮ
8гҖҒи®Ўз®—жҺ’еәҸеҗ‘йҮҸI
еҲ°зӣ®еүҚдёәжӯўпјҢжҲ‘们жүҖи®Ёи®әзҡ„зңӢиө·жқҘжҳҜдёҖдёӘеҫҲжЈ’зҡ„зҗҶи®әпјҢ然иҖҢиҰҒзҹҘйҒ“пјҢжҲ‘们йңҖиҰҒе°ҶиҝҷдёӘж–№жі•еә”з”ЁеҲ°дёҖдёӘз»ҙж•°nзәҰдёә250дәҝзҡ„nГ—n зҹ©йҳөпјҒдәӢе®һдёҠпјҢе№Ӯжі•зү№еҲ«йҖӮз”ЁдәҺиҝҷз§Қжғ…еҪўгҖӮ
еӣһжғійҡҸжңәзҹ©йҳөSеҸҜд»ҘеҶҷжҲҗдёӢиҝ°еҪўејҸ
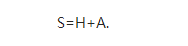
д»ҺиҖҢи°·жӯҢзҹ©йҳөжңүеҰӮдёӢеҪўејҸ

е…¶дёӯJжҳҜе…ғзҙ е…Ёдёә1зҡ„зҹ©йҳөпјҢд»ҺиҖҢ
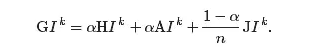
зҺ°еңЁжіЁж„ҸеҲ°пјҢзҹ©йҳөHзҡ„з»қеӨ§йғЁеҲҶе…ғйғҪжҳҜ0пјӣе№іеқҮиҖҢиЁҖпјҢдёҖеҲ—дёӯеҸӘжңү10дёӘе…ғжҳҜйқһйӣ¶ж•°гҖӮд»ҺиҖҢпјҢжұӮHI^k зҡ„жҜҸдёӘе…ғж—¶пјҢеҸӘйңҖиҰҒзҹҘйҒ“10дёӘйЎ№еҚіеҸҜгҖӮиҖҢдё”пјҢе’Ңзҹ©йҳөJдёҖж ·пјҢзҹ©йҳөAзҡ„иЎҢе…ғзҙ йғҪжҳҜзӣёеҗҢзҡ„гҖӮд»ҺиҖҢпјҢжұӮAI^k дёҺJI^k зӣёеҪ“дәҺж·»еҠ жӮ¬жҢӮзӮ№жҲ–иҖ…жүҖжңүзҪ‘йЎөзҡ„еҪ“еүҚйҮҚиҰҒжҖ§жҺ’еәҸеҖјгҖӮиҖҢиҝҷеҸӘйңҖиҰҒдёҖж¬ЎеҚіеҸҜе®ҢжҲҗгҖӮ
еҪ“Оұ еҸ–еҖјжҺҘиҝ‘дәҺ0.85пјҢеёғжһ—е’ҢдҪ©еҘҮжҢҮеҮәпјҢйңҖиҰҒ50еҲ°100ж¬Ўиҝӯд»ЈжқҘиҺ·еҫ—еҜ№еҗ‘йҮҸIзҡ„дёҖдёӘи¶іеӨҹеҘҪзҡ„иҝ‘дјјгҖӮи®Ўз®—еҲ°иҝҷдёӘжңҖдјҳеҖјйңҖиҰҒеҮ еӨ©жүҚиғҪе®ҢжҲҗгҖӮ
еҪ“然пјҢзҪ‘з»ңжҳҜдёҚж–ӯеҸҳеҢ–зҡ„гҖӮйҰ–е…ҲпјҢзҪ‘йЎөзҡ„еҶ…е®№пјҢе°Өе…¶жҳҜж–°й—»еҶ…е®№пјҢеҸҳеҠЁйў‘з№ҒгҖӮе…¶ж¬ЎпјҢзҪ‘з»ңзҡ„йҡҗеҗ«и¶…й“ҫз»“жһ„еңЁзҪ‘йЎөжҲ–й“ҫжҺҘиў«еҠ е…ҘжҲ–иў«еҲ йҷӨж—¶д№ҹиҰҒзӣёеә”еҸҳеҠЁгҖӮжңүдј й—»иҜҙпјҢи°·жӯҢеӨ§зәҰ1дёӘжңҲе°ұиҰҒйҮҚж–°и®Ўз®—дёҖж¬ЎзҪ‘йЎөжҺ’еәҸеҗ‘йҮҸIгҖӮз”ұдәҺеңЁжӯӨжңҹй—ҙеҸҜд»ҘзңӢеҲ°зҪ‘йЎөжҺ’еәҸеҖјдјҡжңүдёҖдёӘжҳҺжҳҫзҡ„жіўеҠЁпјҢдёҖдәӣдәәдҫҝе°Ҷе…¶з§°дёәи°·жӯҢиҲһдјҡпјҲGoogle DanceпјүгҖӮ
9гҖҒжҖ»з»“
еёғжһ—е’ҢдҪ©еҘҮеңЁ1998е№ҙеҲӣе»әдәҶи°·жӯҢпјҢжӯЈеҖјзҪ‘з»ңзҡ„еўһй•ҝжӯҘдјҗе·Із»Ҹи¶…иҝҮеҪ“ж—¶жҗңзҙўеј•ж“Һзҡ„иғҪеҠӣиҢғеӣҙгҖӮеңЁйӮЈдёӘж—¶д»ЈпјҢеӨ§еӨҡж•°зҡ„жҗңзҙўеј•ж“ҺйғҪжҳҜз”ұйӮЈдәӣжІЎе…ҙи¶ЈеҸ‘еёғе…¶дә§е“ҒиҝҗдҪңз»ҶиҠӮзҡ„дјҒдёҡз ”еҸ‘зҡ„гҖӮеңЁеҸ‘еұ•и°·жӯҢзҡ„иҝҮзЁӢдёӯпјҢеёғжһ—е’ҢдҪ©еҘҮеёҢжңӣвҖңжҺЁеҠЁеӯҰжңҜйўҶеҹҹжӣҙеӨҡзҡ„еҸ‘еұ•е’Ңи®ӨиҜҶгҖӮвҖқжҚўиЁҖд№ӢпјҢ他们йҰ–е…ҲеёҢжңӣпјҢе°Ҷжҗңзҙўеј•ж“Һеј•е…ҘдёҖдёӘжӣҙејҖж”ҫзҡ„гҖҒжӣҙеӯҰжңҜеҢ–зҡ„зҺҜеўғпјҢжқҘж”№иҝӣжҗңзҙўеј•ж“Һзҡ„и®ҫи®ЎгҖӮе…¶ж¬ЎпјҢ他们ж„ҹеҲ°е…¶жҗңзҙўеј•ж“Һдә§з”ҹзҡ„з»ҹи®Ўж•°жҚ®иғҪеӨҹдёәеӯҰжңҜз ”з©¶жҸҗдҫӣеҫҲеӨҡзҡ„жңүи¶ЈдҝЎжҒҜгҖӮзңӢжқҘпјҢиҒ”йӮҰж”ҝеәңжңҖиҝ‘иҜ•еӣҫиҺ·еҫ—и°·жӯҢзҡ„дёҖдәӣз»ҹи®Ўж•°жҚ®пјҢд№ҹжҳҜеҗҢж ·зҡ„жғіжі•гҖӮ
иҝҳжңүдёҖдәӣе…¶д»–дҪҝз”ЁзҪ‘з»ңзҡ„и¶…й“ҫз»“жһ„жқҘиҝӣиЎҢзҪ‘йЎөжҺ’еәҸзҡ„з®—жі•гҖӮеҖјеҫ—дёҖжҸҗзҡ„дҫӢеӯҗжҳҜHITSз®—жі•пјҢз”ұд№”жҒ©В·е…ӢиҺұеӣ дјҜж јпјҲJon KleinbergпјүжҸҗеҮәпјҢе®ғжҳҜTeomaжҗңзҙўеј•ж“Һзҡ„еҹәзЎҖгҖӮдәӢе®һдёҠпјҢдёҖдёӘжңүж„ҸжҖқзҡ„дәӢжғ…жҳҜжҜ”иҫғдёҖдёӢдёҚеҗҢжҗңзҙўеј•ж“ҺиҺ·еҫ—зҡ„жҗңзҙўз»“жһңпјҢиҝҷд№ҹеҸҜд»Ҙеё®еҠ©жҲ‘们зҗҶи§Јдёәд»Җд№ҲжңүдәәдјҡжҠұжҖЁи°·жӯҢеҜЎеӨҙпјҲGoogleopolyпјүгҖӮ
viaпјҡдҪң иҖ…:David Austin
зҝ»иҜ‘пјҡжІҲж ӢпјҢеҢ—дә¬еҢ–е·ҘеӨ§еӯҰеүҜж•ҷжҺҲ
ж ЎеҜ№пјҡжұӨж¶ӣпјҢйҰҷжёҜжөёдјҡеӨ§еӯҰж•°еӯҰи®Іеә§ж•ҷжҺҲ

В·ж°§еҲҶеӯҗзҪ‘пјҲhttp://www.yangfenzi.comпјү延伸йҳ…иҜ»пјҡ
ж•°еӯҰжұҹж№–пјҡдёҳжҲҗжЎҗе’ҢеҢ—еӨ§зҡ„жҒ©жҖЁ
иҮӘ然з•Ңе…ӯеӨ§з®—жңҜеӨ§еёҲпјҡжө·иұҡжҳҜвҖңж•°еӯҰеӨ©жүҚвҖқ
зңӢж•°еӯҰеӨ©жүҚеҰӮдҪ•еҲ©з”ЁдәӨеҸӢзҪ‘з«ҷжүҫеҲ°зңҹзҲұ
гҖҠзҗҶи§ЈжңӘжқҘгҖӢеҢ—еӨ§дё“еңәпјҡж•°еӯҰеӨ§еёҲе·…еі°еҜ№иҜқвҖ”ж•°еӯҰеҲ°еә•жңүжІЎжңүз”Ёпјҹ
еҶҜд»‘з«ҹдёәзғ§и„‘жҙ»еҠЁжңӘжқҘи®әеқӣгҖҠзҗҶи§ЈжңӘжқҘгҖӢз«ҷеҸ°пјҢдҪ ж•ўе®Ңж•ҙзңӢе®Ңеҗ—пјҹ






ж–Ү/зҺӢеӨ©дёҖ & жұ е»әејә
еүҚдәӣе№ҙз»Ҹеёёжңүж–°дәәй—®жҲ‘пјҢжҲ‘ж•°еӯҰдёҚеӨӘеҘҪпјҢиғҪдёҚиғҪеҒҡзј–зЁӢиҝҷд»ҪжңүеүҚйҖ”зҡ„иҒҢдёҡпјҹжҲ‘зҡ„ж•°еӯҰеҹәзЎҖйғҪиҝҳз»ҷеӨ§еӯҰиҖҒеёҲдәҶпјҢиҝҳиғҪдёҚиғҪжҲҗдёәдёҖдёӘдјҳз§Җзҡ„зЁӢеәҸе‘ҳпјҹ
йӮЈж—¶еҖҷжҲ‘зҡ„еӣһзӯ”йҖҡеёёжҳҜгҖҢзј–зЁӢе’Ңж•°жҚ®е…¶е®һе…ізі»дёҚеӨ§пјҢдё»иҰҒжҳҜиҖғеҜҹйҖ»иҫ‘е…ізі»е’Ңжё…жҷ°зҡ„зј–зЁӢжҖқи·ҜгҖҚгҖӮд»ҘеүҚзЎ®е®һжҳҜиҝҷж ·пјҢйҷӨдәҶдёҖдәӣдё“дёҡйўҶеҹҹжҲ–еә•еұӮиҪҜ件дә§е“ҒпјҲжҜ”еҰӮж•°жҚ®еә“пјүпјҢзј–зЁӢиҝҮзЁӢдёӯз”ЁеҲ°зҡ„ж•°еӯҰзҹҘиҜҶйқһеёёе°‘пјҢеҶҚеӨҚжқӮзҡ„йҖ»иҫ‘пјҢйҖҡиҝҮдёҖдәӣж•°жҚ®жЁЎеһӢе’ҢеӨҚжқӮиЎЁиҫҫејҸд№ҹеҸҜд»Ҙе®һзҺ°гҖӮйӮЈдјҳз§ҖзЁӢеәҸе‘ҳе’Ңжҷ®йҖҡзЁӢеәҸе‘ҳзҡ„еҢәеҲ«жҳҜд»Җд№Ҳе‘ўпјҹе®һзҺ°жҳҜеҗҰдјҳйӣ…пјҢиғҪдёҚиғҪжү©еұ•пјҢжҳҜдёҚжҳҜз®ҖжҙҒпјҢжҖ§иғҪеҘҪдёҚеҘҪпјҢжңүжІЎжңүиҖғиҷ‘е®үе…ЁгҖҒејӮеёёгҖҒж—Ҙеҝ—зӯүеңәжҷҜпјҢдҪҶеҠҹиғҪеӨ§е®¶жҳҜйғҪиғҪе®һзҺ°зҡ„гҖӮ
еҚідҪҝжҳҜз®—жі•пјҢе®һйҷ…зј–зЁӢиҝҮзЁӢдёӯз”ЁеҲ°зҡ„еңәжҷҜд№ҹдёҚеӨҡпјҢжңҖеёёз”Ёзҡ„жҺ’еәҸгҖҒдәҢеҲҶжҹҘжүҫгҖҒйҖ’еҪ’пјҢиҝҷдәӣзЁӢеәҸе‘ҳеҹәжң¬йғҪиғҪеҶҷпјҢжӣҙеӨҚжқӮзҡ„з®—жі•пјҢд№ҹиғҪжүҫеҲ°зӣёе…ізҡ„еә“гҖӮиҰҒжұӮеҶҚй«ҳдёҖзӮ№пјҢжҜ”еҰӮиғҪиҝҗз”Ёе№ҝеәҰдјҳз§ҖжҗңзҙўгҖҒеӣҫгҖҒиҙӘе©Әз®—жі•гҖҒеҖ’жҺ’зҙўеј•зӯүзӯүпјҢиҝҷдәӣжІЎжңүж•°еӯҰеҹәзЎҖпјҢдёҖж ·дёҖиә«жӯЈж°”пјҢзЁӢеәҸе‘ҳ们зүўи®°пјҢд»ҒиҖ…ж— ж•Ң~~
еҘҪж—ҘеӯҗеҫҲеҝ«е°ұиҝҮеҺ»дәҶвҖҰвҖҰ
еңЁжңәеҷЁеӯҰд№ е’Ңж·ұеәҰеӯҰд№ е·Із»Ҹеә”з”ЁеҲ°еҗ„дёӘйўҶеҹҹзҡ„д»ҠеӨ©пјҢеҰӮжһңдҪ жғіе…Ҙй—Ёдәәе·ҘжҷәиғҪпјҢдёҚжҮӮж•°еӯҰеҹәжң¬дёҠе°ұеҫҲиү°йҡҫдәҶгҖӮдёҚдәҶи§ЈжҰӮзҺҮи®әгҖҒж•°еҖјеҲҶжһҗе’ҢзәҝжҖ§д»Јж•°пјҢдҪ е°ұеҫҲйҡҫзңӢжҮӮеҲ«дәәеӯҰд№ еҮәжқҘзҡ„жЁЎеһӢпјҢж— жі•и°ғж•ҙеҸӮж•°зңӢж•°жҚ®з»“жһңпјҢзңӢд№ҹзңӢдёҚжҳҺзҷҪгҖӮеҫҲеӨҡдәәеҺ»иҜ» AI зӣёе…ізҡ„и®әж–ҮпјҢе·Із»Ҹе…ЁйғЁжҳҜзҝ»иҜ‘иҝҮжқҘзҡ„дёӯж–ҮдәҶпјҢйҷӨдәҶж•°еӯҰе…¬ејҸе…ЁжҳҜдёӯеӣҪеӯ—пјҢе°ұжҳҜдёҚзҹҘйҒ“е•Ҙж„ҸжҖқгҖӮ
дёәдәҶи§ЈеҶіиҝҷдёӘжЁӘдәҳеңЁзЁӢеәҸе‘ҳе’Ң AI е·ҘзЁӢеёҲд№Ӣй—ҙзҡ„еӨ§еұұпјҢжҲ‘们йӮҖиҜ·дәҶзҺӢеӨ©дёҖж•ҷжҺҲејҖдәҶдёҖй—ЁгҖҢдәәе·ҘжҷәиғҪеҹәзЎҖиҜҫгҖҚпјҢеҲҶдә«дәәе·ҘжҷәиғҪзҡ„еҹәзЎҖзҹҘиҜҶпјҲе°Өе…¶жҳҜж•°еӯҰпјүпјҢд»Ҙеё®еҠ©зЁӢеәҸе‘ҳ们жӣҙеҘҪзҡ„еӯҰд№ е’ҢзҗҶи§Јдәәе·ҘжҷәиғҪгҖӮеҗ¬иҝҷдёӘиҜҫе°ұиғҪеӯҰдјҡж•°еӯҰд№Ҳпјҹд№ҹи®ёеҗ§пјҢдёҚдҝЎзҡ„иҜқеҸҜд»Ҙе…ҲиҜ»иҜ»зҺӢж•ҷжҺҲзҡ„иҝҷзҜҮж–Үз« вҖҰвҖҰ
д№қеұӮд№ӢеҸ°пјҢиө·дәҺзҙҜеңҹпјҡзәҝжҖ§д»Јж•°
вҖңдәәе·ҘжҷәиғҪеҹәзЎҖиҜҫвҖқе°Ҷд»Һж•°еӯҰеҹәзЎҖејҖе§ӢгҖӮеҝ…еӨҮзҡ„ж•°еӯҰзҹҘиҜҶжҳҜзҗҶи§Јдәәе·ҘжҷәиғҪдёҚеҸҜжҲ–зјәзҡ„иҰҒзҙ пјҢд»ҠеӨ©зҡ„з§Қз§Қдәәе·ҘжҷәиғҪжҠҖжңҜеҪ’ж №еҲ°еә•йғҪе»әз«ӢеңЁж•°еӯҰжЁЎеһӢд№ӢдёҠпјҢиҖҢиҝҷдәӣж•°еӯҰжЁЎеһӢеҸҲйғҪзҰ»дёҚејҖзәҝжҖ§д»Јж•°зҡ„зҗҶи®әжЎҶжһ¶гҖӮ
дәӢе®һдёҠпјҢзәҝжҖ§д»Јж•°дёҚд»…д»…жҳҜдәәе·ҘжҷәиғҪзҡ„еҹәзЎҖпјҢжӣҙжҳҜзҺ°д»Јж•°еӯҰе’Ңд»ҘзҺ°д»Јж•°еӯҰдҪңдёәдё»иҰҒеҲҶжһҗж–№жі•зҡ„дј—еӨҡеӯҰ科зҡ„еҹәзЎҖгҖӮд»ҺйҮҸеӯҗеҠӣеӯҰеҲ°еӣҫеғҸеӨ„зҗҶйғҪзҰ»дёҚејҖеҗ‘йҮҸе’Ңзҹ©йҳөзҡ„дҪҝз”ЁгҖӮиҖҢеңЁеҗ‘йҮҸе’Ңзҹ©йҳөиғҢеҗҺпјҢзәҝжҖ§д»Јж•°зҡ„ж ёеҝғж„Ҹд№үеңЁдәҺжҸҗдҫӣдәҶвјҖз§ҚзңӢеҫ…дё–з•Ңзҡ„жҠҪиұЎи§Ҷи§’пјҡдёҮдәӢдёҮзү©йғҪеҸҜд»Ҙиў«жҠҪиұЎжҲҗжҹҗдәӣзү№еҫҒзҡ„з»„еҗҲпјҢ并еңЁз”ұйў„зҪ®и§„еҲҷе®ҡд№үзҡ„жЎҶжһ¶д№ӢдёӢд»ҘйқҷжҖҒе’ҢеҠЁжҖҒзҡ„ж–№ејҸеҠ д»Ҙи§ӮеҜҹгҖӮ
зәҝжҖ§д»Јж•°дёӯжңҖеҹәжң¬зҡ„жҰӮеҝөжҳҜйӣҶеҗҲгҖӮеңЁж•°еӯҰдёҠпјҢйӣҶеҗҲзҡ„е®ҡд№үжҳҜз”ұжҹҗдәӣзү№е®ҡеҜ№иұЎжұҮжҖ»иҖҢжҲҗзҡ„йӣҶдҪ“гҖӮйӣҶеҗҲдёӯзҡ„е…ғзҙ йҖҡеёёдјҡе…·жңүжҹҗдәӣе…ұжҖ§пјҢеӣ иҖҢеҸҜд»Ҙз”Ёиҝҷдәӣе…ұжҖ§жқҘиЎЁзӨәгҖӮеҜ№дәҺйӣҶеҗҲ { иӢ№жһңпјҢж©ҳеӯҗпјҢжўЁ } жқҘиҜҙпјҢ жүҖжңүе…ғзҙ зҡ„е…ұжҖ§жҳҜе®ғ们йғҪжҳҜж°ҙжһңпјӣеҜ№дәҺйӣҶеҗҲ {зүӣпјҢ马пјҢзҫҠ} жқҘиҜҙпјҢжүҖжңүе…ғзҙ зҡ„е…ұжҖ§жҳҜе®ғ们йғҪжҳҜеҠЁзү©гҖӮеҪ“然 { иӢ№жһңпјҢзүӣ } д№ҹеҸҜд»Ҙжһ„жҲҗдёҖдёӘйӣҶеҗҲпјҢдҪҶиҝҷдёӨдёӘе…ғзҙ 并没жңүжҳҺжҳҫзҡ„е…ұжҖ§пјҢиҝҷж ·зҡ„йӣҶеҗҲеңЁи§ЈеҶіе®һйҷ…й—®йўҳдёӯзҡ„дҪңз”Ёд№ҹе°ұзӣёеҪ“жңүйҷҗгҖӮ
вҖңиӢ№жһңвҖқжҲ–жҳҜвҖңзүӣвҖқиҝҷж ·зҡ„е…·дҪ“жҰӮеҝөжҳҫ然超еҮәдәҶж•°еӯҰзҡ„еӨ„зҗҶиҢғеӣҙпјҢеӣ иҖҢйӣҶеҗҲзҡ„е…ғзҙ йңҖиҰҒиҝӣиЎҢиҝӣдёҖжӯҘзҡ„жҠҪиұЎвҖ”вҖ”з”Ёж•°еӯ—жҲ–з¬ҰеҸ·жқҘиЎЁзӨәгҖӮеҰӮжӯӨдёҖжқҘпјҢйӣҶеҗҲзҡ„е…ғзҙ ж—ўеҸҜд»ҘжҳҜеҚ•дёӘзҡ„ж•°еӯ—жҲ–з¬ҰеҸ·пјҢд№ҹеҸҜд»ҘжҳҜеӨҡдёӘж•°еӯ—жҲ–з¬ҰеҸ·д»Ҙжҹҗз§Қж–№ејҸжҺ’еҲ—еҪўжҲҗзҡ„з»„еҗҲгҖӮ
еңЁзәҝжҖ§д»Јж•°дёӯпјҢз”ұеҚ•зӢ¬зҡ„ж•° a жһ„жҲҗзҡ„е…ғзҙ иў«з§°дёәж ҮйҮҸпјҡдёҖдёӘж ҮйҮҸ a еҸҜд»ҘжҳҜж•ҙж•°гҖҒе®һж•°жҲ–еӨҚж•°гҖӮеҰӮжһңеӨҡдёӘж ҮйҮҸ a1,a2,вӢҜ,ana1,a2,вӢҜ,an жҢүдёҖе®ҡйЎәеәҸз»„жҲҗдёҖдёӘеәҸеҲ—пјҢиҝҷж ·зҡ„е…ғзҙ е°ұиў«з§°дёәеҗ‘йҮҸгҖӮжҳҫ然пјҢеҗ‘йҮҸеҸҜд»ҘзңӢдҪңж ҮйҮҸзҡ„жү©еұ•гҖӮеҺҹе§Ӣзҡ„дёҖдёӘж•°иў«жӣҝд»ЈдёәдёҖз»„ж•°пјҢд»ҺиҖҢеёҰжқҘдәҶз»ҙеәҰзҡ„еўһеҠ пјҢз»ҷе®ҡиЎЁзӨәзҙўеј•зҡ„дёӢж ҮжүҚиғҪе”ҜдёҖең°зЎ®е®ҡеҗ‘йҮҸдёӯзҡ„е…ғзҙ гҖӮ
жҜҸдёӘеҗ‘йҮҸйғҪз”ұиӢҘе№Іж ҮйҮҸжһ„жҲҗпјҢеҰӮжһңе°Ҷеҗ‘йҮҸзҡ„жүҖжңүж ҮйҮҸйғҪжӣҝжҚўжҲҗзӣёеҗҢи§„ж јзҡ„еҗ‘йҮҸпјҢеҫ—еҲ°зҡ„е°ұжҳҜеҰӮдёӢзҡ„зҹ©йҳө:
вҖҰвҖҰ
дёӯй—ҙзҡ„ж–Үз« жңүйғЁеҲҶе°ҸйғЁеҲҶе…¬ејҸеңЁеҫ®дҝЎйҮҢж— жі•еҫҲеҘҪзҡ„еұ•зӨәпјҢе»әи®®еӨ§е®¶й•ҝжҢүиҜҶеҲ«дәҢз»ҙз Ғйҳ…иҜ»еҺҹж–Үпјҡ
вҖҰвҖҰ
жӯЈеҰӮеүҚж–ҮжүҖиҝ°пјҢзҹ©йҳөд»ЈиЎЁдәҶеҗ‘йҮҸзҡ„еҸҳжҚўпјҢе…¶ж•ҲжһңйҖҡеёёжҳҜеҜ№еҺҹе§Ӣеҗ‘йҮҸеҗҢж—¶ж–ҪеҠ ж–№еҗ‘еҸҳеҢ–е’Ңе°әеәҰеҸҳеҢ–гҖӮеҸҜеҜ№дәҺжңүдәӣзү№ж®Ҡзҡ„еҗ‘йҮҸпјҢзҹ©йҳөзҡ„дҪңз”ЁеҸӘжңүе°әеәҰеҸҳеҢ–иҖҢжІЎжңүж–№еҗ‘еҸҳеҢ–пјҢд№ҹе°ұжҳҜеҸӘжңүдјёзј©зҡ„ж•ҲжһңиҖҢжІЎжңүж—ӢиҪ¬зҡ„ж•ҲжһңгҖӮеҜ№дәҺз»ҷе®ҡзҡ„зҹ©йҳөжқҘиҜҙпјҢиҝҷзұ»зү№ж®Ҡзҡ„еҗ‘йҮҸе°ұжҳҜзҹ©йҳөзҡ„зү№еҫҒеҗ‘йҮҸпјҢзү№еҫҒеҗ‘йҮҸзҡ„е°әеәҰеҸҳеҢ–зі»ж•°е°ұжҳҜзү№еҫҒеҖјгҖӮ
зҹ©йҳөзү№еҫҒеҖје’Ңзү№еҫҒеҗ‘йҮҸзҡ„еҠЁжҖҒж„Ҹд№үеңЁдәҺиЎЁзӨәдәҶеҸҳеҢ–зҡ„йҖҹеәҰе’Ңж–№еҗ‘гҖӮеҰӮжһңжҠҠзҹ©йҳөжүҖд»ЈиЎЁзҡ„еҸҳеҢ–зңӢдҪңеҘ”и·‘зҡ„дәәпјҢйӮЈд№Ҳзҹ©йҳөзҡ„зү№еҫҒеҖје°ұд»ЈиЎЁдәҶд»–еҘ”и·‘зҡ„йҖҹеәҰпјҢзү№еҫҒеҗ‘йҮҸд»ЈиЎЁдәҶд»–еҘ”и·‘зҡ„ж–№еҗ‘гҖӮдҪҶзҹ©йҳөеҸҜдёҚжҳҜжҷ®йҖҡдәәпјҢе®ғжҳҜдёүеӨҙе…ӯиҮӮзҡ„е“Әеҗ’пјҢд»–зҡ„дёҚеҗҢеҲҶиә«д»ҘдёҚеҗҢйҖҹеәҰпјҲзү№еҫҒеҖјпјүеңЁдёҚеҗҢж–№еҗ‘пјҲзү№еҫҒеҗ‘йҮҸпјүдёҠеҘ”и·‘пјҢжүҖжңүеҲҶиә«зҡ„иҝҗеҠЁеҸ еҠ еңЁвјҖиө·жүҚжҳҜзҹ©йҳөзҡ„ж•ҲжһңгҖӮ
жұӮи§Јз»ҷе®ҡзҹ©йҳөзҡ„зү№еҫҒеҖје’Ңзү№еҫҒеҗ‘йҮҸзҡ„иҝҮзЁӢеҸ«еҒҡзү№еҫҒеҖјеҲҶи§ЈпјҢдҪҶиғҪеӨҹиҝӣиЎҢзү№еҫҒеҖјеҲҶи§Јзҡ„зҹ©йҳөеҝ…йЎ»жҳҜ n з»ҙж–№йҳөгҖӮе°Ҷзү№еҫҒеҖјеҲҶи§Јз®—жі•жҺЁе№ҝеҲ°жүҖжңүзҹ©йҳөд№ӢдёҠпјҢе°ұжҳҜжӣҙеҠ йҖҡз”Ёзҡ„еҘҮејӮеҖјеҲҶи§ЈгҖӮ
д»ҠеӨ©жҲ‘е’ҢдҪ еҲҶдә«дәҶдәәе·ҘжҷәиғҪеҝ…еӨҮзҡ„зәҝжҖ§д»Јж•°еҹәзЎҖпјҢзқҖйҮҚдәҺжҠҪиұЎжҰӮеҝөзҡ„и§ЈйҮҠиҖҢйқһе…·дҪ“зҡ„ж•°еӯҰе…¬ејҸпјҢе…¶иҰҒзӮ№еҰӮдёӢпјҡ
зәҝжҖ§д»Јж•°зҡ„жң¬иҙЁеңЁдәҺе°Ҷе…·дҪ“дәӢзү©жҠҪиұЎдёәж•°еӯҰеҜ№иұЎпјҢ并жҸҸиҝ°е…¶йқҷжҖҒе’ҢеҠЁжҖҒзҡ„зү№жҖ§пјӣ
еҗ‘йҮҸзҡ„е®һиҙЁжҳҜ n з»ҙзәҝжҖ§з©әй—ҙдёӯзҡ„йқҷжӯўзӮ№пјӣ
зәҝжҖ§еҸҳжҚўжҸҸиҝ°дәҶеҗ‘йҮҸжҲ–иҖ…дҪңдёәеҸӮиҖғзі»зҡ„еқҗж Үзі»зҡ„еҸҳеҢ–пјҢеҸҜд»Ҙз”Ёзҹ©йҳөиЎЁзӨәпјӣ
зҹ©йҳөзҡ„зү№еҫҒеҖје’Ңзү№еҫҒеҗ‘йҮҸжҸҸиҝ°дәҶеҸҳеҢ–зҡ„йҖҹеәҰдёҺж–№еҗ‘гҖӮ
зәҝжҖ§д»Јж•°д№ӢдәҺдәәе·ҘжҷәиғҪеҰӮеҗҢеҠ жі•д№ӢдәҺй«ҳзӯүж•°еӯҰгҖӮиҝҷж ·дёҖдёӘеҹәзЎҖзҡ„е·Ҙе…·йӣҶпјҢдҪ иғҪжғіеҲ°е®ғеңЁдәәе·ҘжҷәиғҪдёӯзҡ„е“Әдәӣе…·дҪ“еә”з”Ёе‘ўпјҹ